生物群集の種個体数分布をWeibull分布で説明する論文をEcological Complexity に発表しました(50 days' free access)。
生物群集の”種個体数分布”(SAD: species abundance distribution)は、種の個体数に関する普遍性(commonness)や希少性(rarity)を表す種多様性パターンで、古くから注目されてきました。野外調査で得られた種個体数データに様々な統計モデルを当てはめて、統計分布の特性に基づいて種個体数分布を説明する生態学的プロセス(ニッチ集合や分散集合など)が議論されてきました。古典的な統計モデルとして、プレストンの対数正規分布やフィシャーの対数級数分布などがありますが、その他にも、種個体数分布を説明する数多くの統計分布が提唱され、最近では、Gambinモデルのような、より柔軟(flexible)な性質の統計モデルも議論されています。
生物群集の”種個体数分布”(SAD: species abundance distribution)は、種の個体数に関する普遍性(commonness)や希少性(rarity)を表す種多様性パターンで、古くから注目されてきました。野外調査で得られた種個体数データに様々な統計モデルを当てはめて、統計分布の特性に基づいて種個体数分布を説明する生態学的プロセス(ニッチ集合や分散集合など)が議論されてきました。古典的な統計モデルとして、プレストンの対数正規分布やフィシャーの対数級数分布などがありますが、その他にも、種個体数分布を説明する数多くの統計分布が提唱され、最近では、Gambinモデルのような、より柔軟(flexible)な性質の統計モデルも議論されています。

この論文では、柔軟なモデルであるワイブル分布と古典的統計モデルを階層的に利用して、多様な種個体数分布を生態学的に解釈することを試みました。
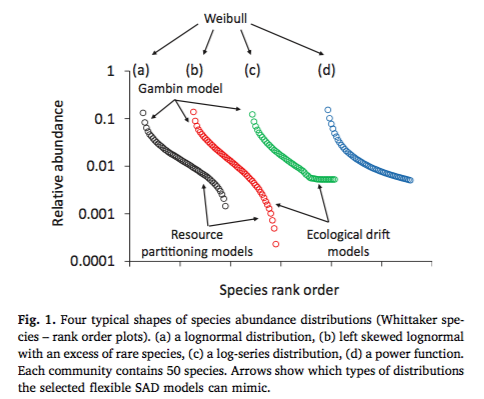
Weibull分布のパラメータは、ガンマ分布に基づいたスケールパラメータ λとシェープパラメータηで定式化されます。さらに、これらのパラメータは生態学的に解釈することができるので(λは均等度、ηはrarity/commonness)、群集生態学的に便利な統計分布なのです。もしWeibull分布が種個体数分布によく当てはまるのであれば、λ(均等度)やη(rarity/commonness)に基づいて種のパッキングやニッチ分割のプロセスを推論できます。実際、森林群集プロットで観測された樹木種の個体数データに対するWeibull分布の当てはまりは非常に良くて、スケールパラメータλとシェープパラメータηの組み合わせには制約があり、種個体数分布には生態学的には生じ得ない””fobiddenパターン”が存在することも示唆されました:スケールパラメータλはアバンダンスレンジと相関して、シェープパラメータηは3以上の値にはならない。
種個体数分布のような観測データに統計モデルを当てはめる分析アプローチは、生態学では頻繁に行われます。統計モデルの当てはめの動機は、生態学的な現象やパターンの”予測”だと思います。例えば、プレストンは、種個体数データが生物群集(母集団)のサンプルであるという観点から、対数正規分布を当てはめて、観測されていない未知種の存在を考慮した”真の多様性”の予測を可能にしました。さらに、種個体数データに当てはまるユニバーサルな統計モデルが見いだせたら、種個体数データの背後にある群集集合の一般的メカニズムを推論することに発展します。これは、プレストン、フィッシャーからハベルの中立モデルに至る種個体数分布研究の歴史として観ることができるでしょう。
しかし、「種個体数分布を説明する一般的な統計モデルがはっきりしない」、「ユニバーサルに当てはまりのいいモデルがない」あるいは「複数のモデルが同じように当てはまる」といった、堂々巡りな研究が続いているのも事実です。このような問題意識を元にして、多様な種個体数分布パターンを説明する様々な統計モデルを階層的に捉えて、モデルパラメータに基づいて群集形成プロセスを解釈するアプローチを考えています。
種個体数分布のような観測データに統計モデルを当てはめる分析アプローチは、生態学では頻繁に行われます。統計モデルの当てはめの動機は、生態学的な現象やパターンの”予測”だと思います。例えば、プレストンは、種個体数データが生物群集(母集団)のサンプルであるという観点から、対数正規分布を当てはめて、観測されていない未知種の存在を考慮した”真の多様性”の予測を可能にしました。さらに、種個体数データに当てはまるユニバーサルな統計モデルが見いだせたら、種個体数データの背後にある群集集合の一般的メカニズムを推論することに発展します。これは、プレストン、フィッシャーからハベルの中立モデルに至る種個体数分布研究の歴史として観ることができるでしょう。
しかし、「種個体数分布を説明する一般的な統計モデルがはっきりしない」、「ユニバーサルに当てはまりのいいモデルがない」あるいは「複数のモデルが同じように当てはまる」といった、堂々巡りな研究が続いているのも事実です。このような問題意識を元にして、多様な種個体数分布パターンを説明する様々な統計モデルを階層的に捉えて、モデルパラメータに基づいて群集形成プロセスを解釈するアプローチを考えています。

 RSS Feed
RSS Feed
